 Follow
FollowGenau vor einem Jahr, zum Mauerfall-Jubiläum, hatten wir mit „Wer kam, wer ging, wer heute hier wohnt“ Wanderungsdaten ausgewertet, um zu zeigen, wie sich die Berliner in den vergangenen 25 Jahren verändert haben. Jetzt zeigen wir mit „Berlins neuer Skyline“, wie sich Berlin selbst in diesem Zeitraum verändert hat – und wie es in Zukunft aussehen soll.
Inspiriert von dem Stück „Reshaping New York“ der New York Times begannen wir bereits vor mehr als einem Jahr mit der ersten Daten-Recherche. Unsere erste Idee: Wir benötigen einen aktuellen Datensatz mit allen Berliner Gebäuden mit jeweiliger Höhe und Baujahr.
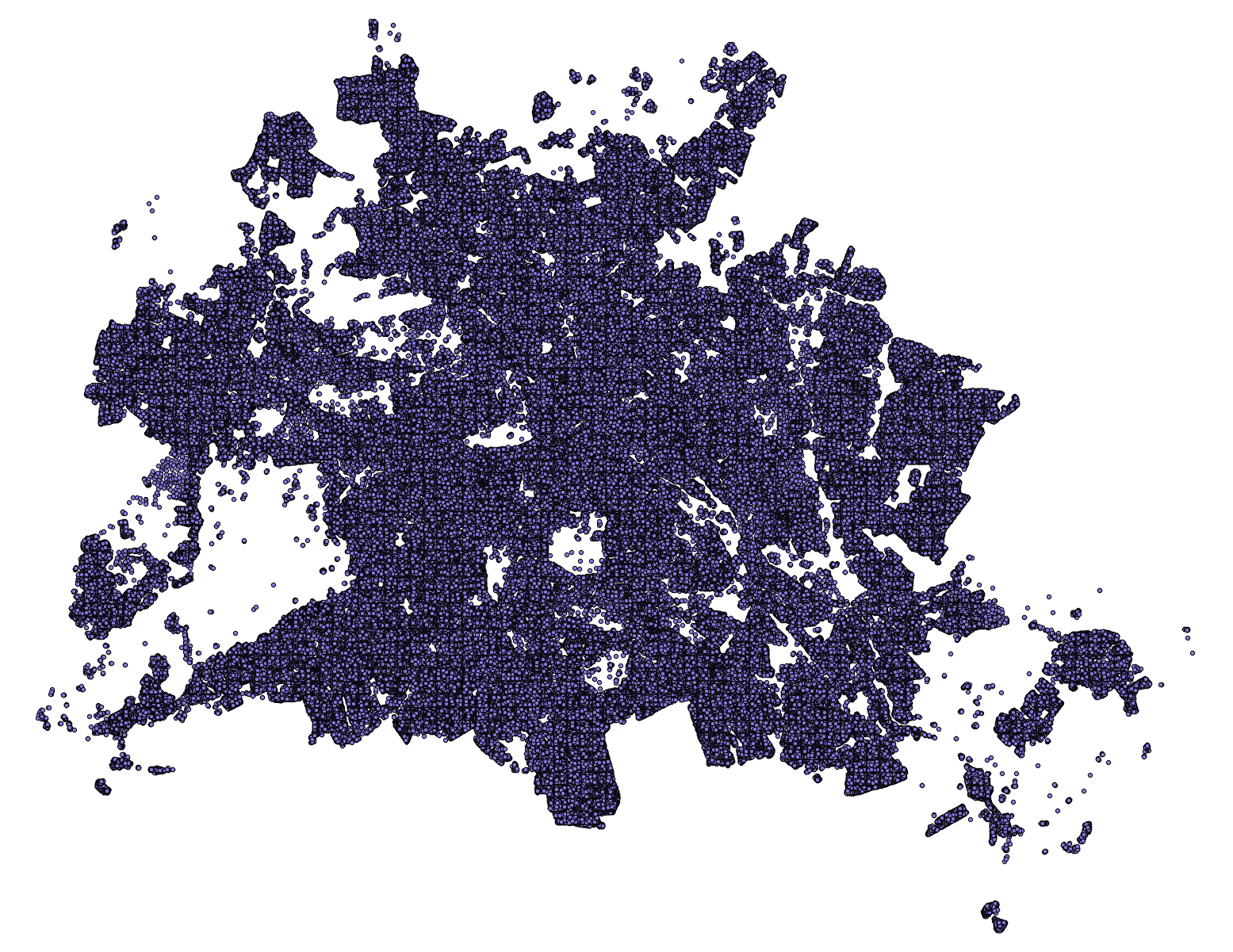
Rund eine Million Punkte mit Geschosszahlen in römischen Ziffern
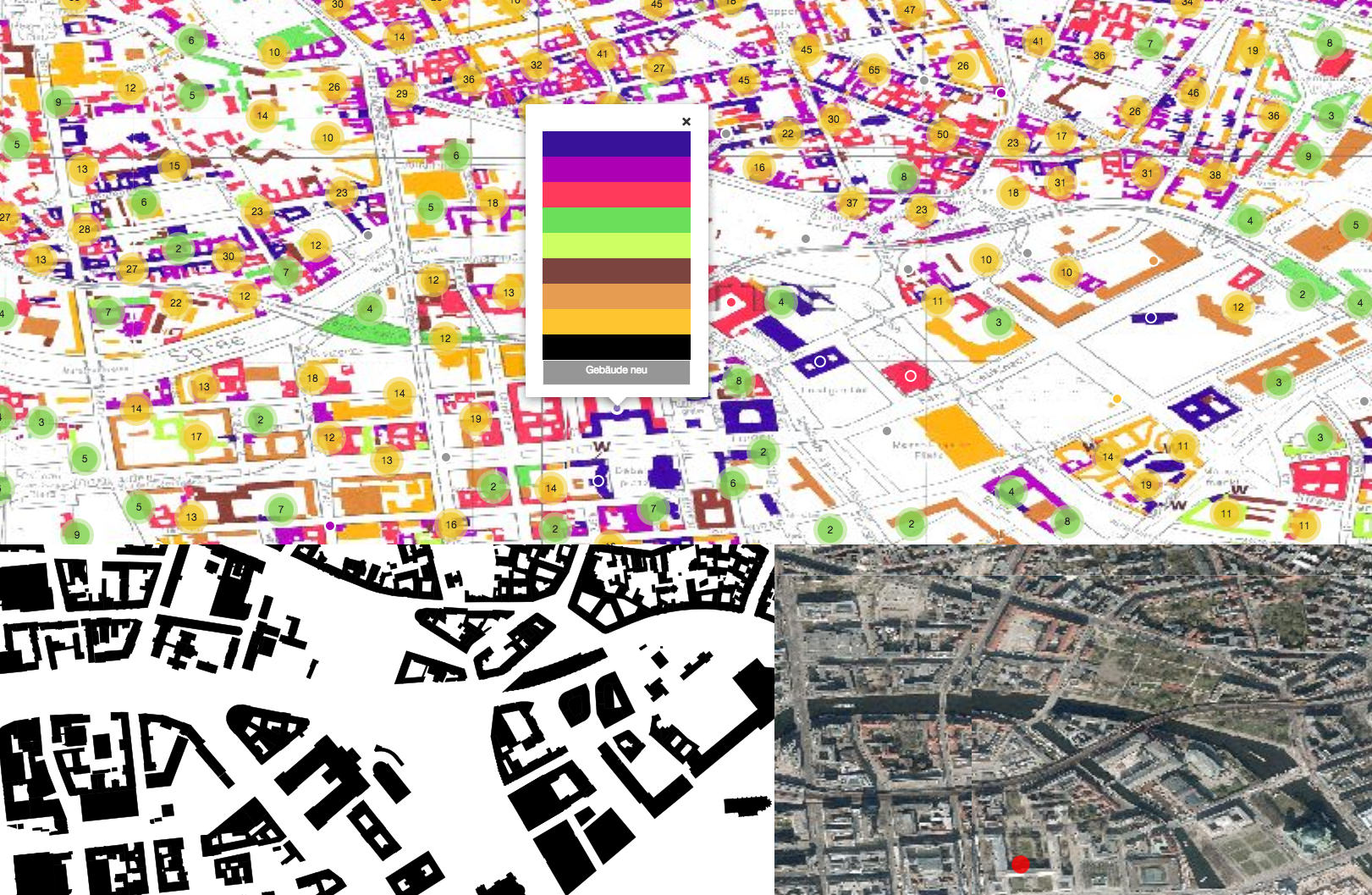
Zwar gibt es mit dem aktuellen Automatisierten Liegenschaftskataster (ALK) einen Datensatz aller Gebäude Berlins mit entsprechenden Höhen. Den Datensatz konnten wir in Form einer DVD direkt bei der Berliner Senatsumweltbehörde bekommen. Google, Open Street Maps o.ä. verfügen auch über die Gebäude in Berlin. Wir wollten allerdings den wirklich aktuellsten und offiziellen Stand der Stadt. Dieser stellte sich aber als äußerst sperrig heraus. So waren etwa die Höhenangaben in römischen Ziffern in einer Punktwolke in dem Shapefile hinterlegt (siehe Screenshot). Darüber hinaus handelt es sich bei dem Datensatz um Grundflächen, die entsprechenden extrudiert werden – was ein sehr schematisches Bild der Stadt abgegeben hätte (z.B. besteht der Fernsehturm lediglich aus einem rund 300 Meter hohen Zylinder).
Noch problematischer war, an das Gebäudealter zu kommen. Für viele Städte gibt es solche Datensätze, wie etwa für die Niederlande. Weltweit sind bereits mehrere Visualisierungen zum Gebäudealter in Städten entstanden. Berlinweit gibt es einen solchen nicht. Über eine Datenbank der bulwiengesa kommt man nur an die Baujahre von Großprojekten. Wenn man die Baujahre der entsprechenden Angebote auf Wohnungsportalen scrapt, bekommt man nur ein sehr unvollständiges Bild.
Eigenes Tool, um das Gebäudealter zu digitalisieren
Berlin stellt nur einen handgezeichneten Plan mit Stand 1992/93, in dem Gebäude innerhalb des S-Bahn-Rings nach bestimmten Altersklassen eingezeichnet sind, im WMS-Format zur Verfügung. Dafür programmierte Moritz Klack ein Tool, das an den jeweiligen Mittelpunkten der aktuellen Gebäude die entsprechende Farbe der Rasterdatei findet und speichert. Mit einem weiteren Tool konnten diese Ergebnisse überprüft und kleine Fehler korrigiert werden. Letztendlich war uns der Datensatz nicht exakt genug, um damit weitere Aussagen treffen zu können. Wir planen aber ein Crowdsourcing-Projekt mit diesen Daten.
Bei der weiteren Recherche stießen wir auf das 3D-Modell der Senatsumweltbehörde. Darin sind sowohl die exakten Gebäudestrukturen als auch die Alterseinteilung „vor 1990 gebaut“, „nach 1990 gebaut“, „geplant“ und „vorgeschlagen“ enthalten. Also alle wichtigen Informationen für unsere interaktive Anwendung. Der Nachteil: Es handelte sich nur um die Gebäude innerhalb des sogenannten „Planwerk Innere Stadt“, etwa einem Drittel innerhalb des Berliner S-Bahn-Rings. Außerdem handelte es sich bei den Daten um ein proprietäres AutoCAD-Format in einer riesigen Datenmenge vor.
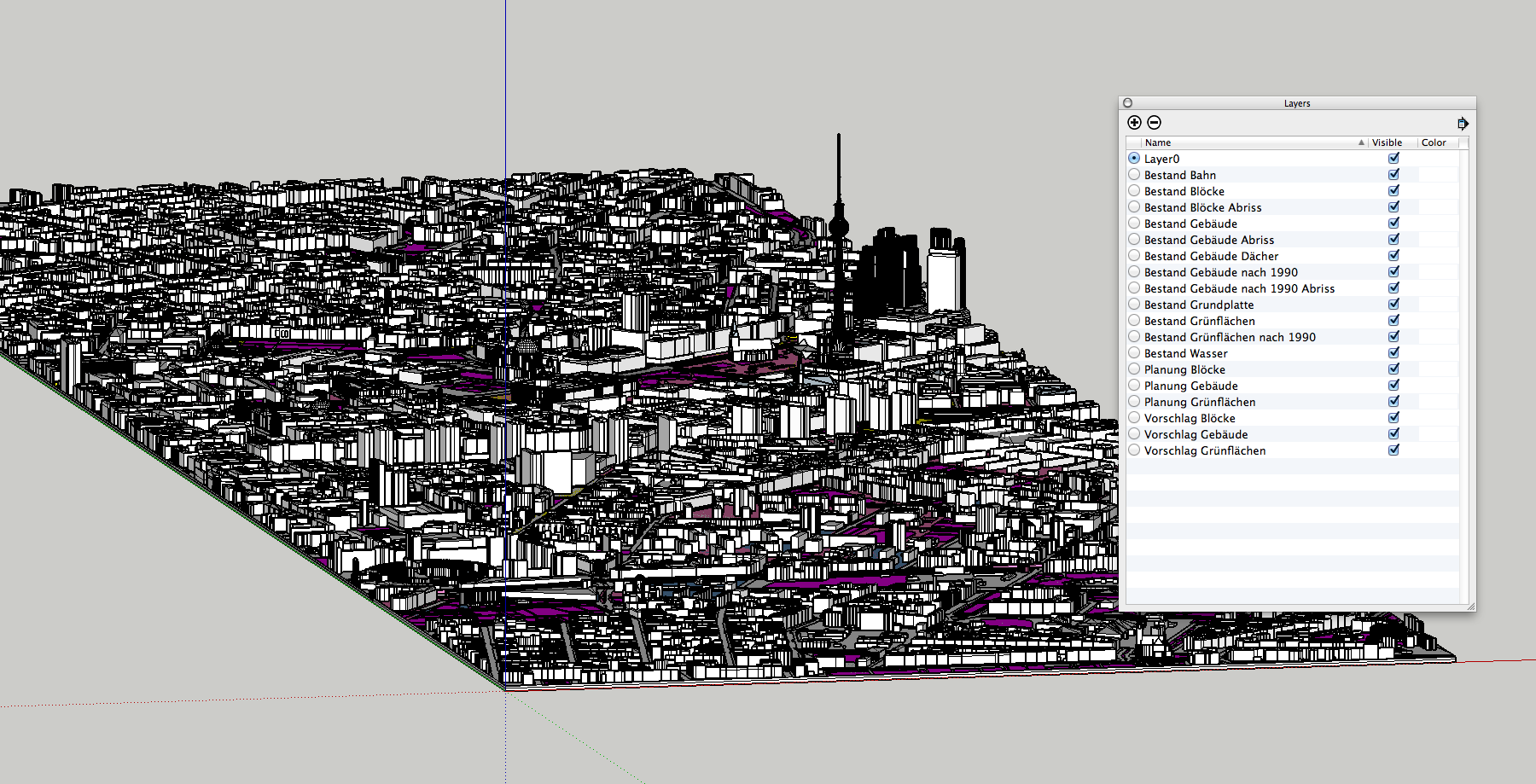
Original 3D-Modell der Stadt Berlin in Sketchup
Auf Anfrage erhielten wir von der Stadt ein aktuelles Modell mit Stand September 2015, was uns sehr wichtig war, da sich die Planungen in Berlin ständig ändern. Um die Datenmenge zu verkleinern, entfernten wir in einem ersten Schritt unnötige Details wie Grünflächen. Dafür importierten wir das AutoCAD-Format der Stadt in die 3D-Software Sketchup und exportierten diese wiederum im OBJ-Format.
Um das rund 800 MB große Stadtmodell ins Web zu bringen, arbeiteten wir mit Jan Marsch von OSM Buildings zusammen. Er gehört zu den bekanntesten Experten auf diesem Gebiet und schaffte es, die Datenmenge drastisch zu reduzieren. Außerdem entwickelte er exklusiv für uns neue Features wie etwa 3D-Labels, die nun auch von allen benutzt werden können. In unserem Fall erstellte er aus den von uns bereitgestellten OBJ-Dateien GeoJSON. Den technischen Prozess beschreibt er in einem eigenen Blogbeitrag. Wer selbst ein solches 3D-Projekt umsetzen möchte, kann den Code bei Github einsehen und nutzen.
Dieses GeoJSON wiederum brachten wir bei uns auf eigene Kacheln, wie es bei interaktiven Karten üblich ist, um die Ladegeschwindigkeit deutlich zu erhöhen. Diesen Prozess beschreiben Christopher Möller und Moritz Klack in einem eigenen Blogbeitrag. Außerdem konnten wir mit diesem Dateiformat nun Geo-Berechnungen in QGIS vornehmen. So fanden wir heraus, welche Fläche in Berlins Innenstadt bereits bebaut ist – und weiter bebaut werden könnte. Diese Information gibt es nicht von der Stadt.

Weiteres 3D-Modell Berlins als Open Data
Zwischenzeitlich veröffentlichte die Stadt ein weiteres 3D-Modell als Open Data, diesmal von der Senatsverwaltung für Wirtschaft, Technologie und Forschung. Dieses deckt in hohem Detailgrad (LoD2) die gesamte Stadt ab und enthält sogar realistische Texturen für die Gebäude. Allerdings kam es für unsere Geschichte aufgrund des fehlenden Gebäudealters nicht in Betracht. Im Rahmen eines Hackdays wurden aber interessante Projekte damit verwirklicht.

Das Intro-Video als Sprite für Canvid
Wie bei vielen unseren Projekten war die mobile Version zuerst fertig. Um dort Videos automatisch entsprechend der Stelle im Text abspielen lassen zu können, nutzten wir die Bibliothek Canvid von Gregor Aisch und Moritz Klack. Diese wird auch öfters bei der New York Times eingesetzt, um das Autoplay-Verbot von Videos auf iOS-Geräten zu umgehen. Dafür werden Videos per ffmpeg in einzelne Frames zerlegt und mit ImageMagick zu einem großen Sprite zusammengebaut.
Früh war uns klar, dass wir uns bei der Geschichte darauf konzentrieren, wo Berlin in die höhe wächst, wo Wolkenkratzer gebaut wurden und noch gebaut werden – wo also das Stadtbild nachhaltig verändert wird. Dafür ergibt die Darstellung in 3D in unseren Augen absolut Sinn. Für geringere Ladezeiten und höhere Performance – nicht alle Browser und Rechner unterstützen die WebGL-Technik – zeigten wir Videos mit einer optionalen interaktiven Version. Diese ruckelte doch ganz ordentlich auf dem einen oder anderen Rechner. Allerdings gab es nach dem Launch keinerlei Kritik an der Performance.
3D-Daten interaktiv fürs Web aufzubereiten ist äußerst umfangreich. Wir haben dabei selbst viel über Formate und neue Web-Technologien gelernt und freuen uns sehr darüber, dass die Geschichte bei den Lesern bisher – betrachtet man etwa die hohen Sharing-Zahlen auf Facebook – sehr gut ankommt.