Ich finde ja, man sollte nie aufhören zu lernen. Deshalb gehe ich für einen Monat nach New York. Dort werde ich jeweils zwei Wochen bei Propublica und dem Guardian arbeiten.
")
Sonnenuntergang mit Blick aus dem Propublica-Büro. Foto: Dan Nguyen (CC)
Bei Propublica nehme ich an dem P5 (Propublica Pair Programming Project) teil. Dabei werde ich mit Scott Klein und seinem Team, bestehend aus Journalisten und Programmierern, an einem Datenprojekt, einer News App arbeiten. Eine News App „is a web-based interactive database that tells a journalistic story using software instead of words and pictures.“
Danach geht es vom Financial District ein paar Straßen nördlich in SoHo bei der US-Ausgabe des Guardian weiter. Dort unterstütze ich das Open-Team um Amanda Michel bei einem Interaktiv-Projekt.
Am 9. November geht’s los. Ich freue mich schon jetzt auf das intensive Datenjournalismus-Bootcamp.
Warum ich das hier schreibe? In der Vorbereitungszeit und während meines Aufenthalts werde ich über das, was ich lerne, auch hier auf digitalerwandel.de bloggen.
Ich freue mich über Anregungen und Kritik zu dem Beitrag aber auch jeden New-York-Tipp in den Kommentaren, bei Facebook, Twitter und Google+.
+++ Donnerstag, 13. Dezember, Berlin +++
Seit Donnerstag bin ich wieder zuhause in Berlin. Es war ein intensiver Monat, in dem ich einerseits sehr viel gelernt habe und andererseits viele tolle Menschen kennenlernen durfte. Vielen Dank vor allem an Scott Klein, Al Shaw, Jeff Larsson, Lena Groeger, Mark Schoofs, Gabriel Dance, Amanda Michel, Julian Burgess und Feilding Cage.

Mein Gastgeschenk an die Kollegen
Neben Ruby on Rails und Datenbanken waren da auch die Thanksgiving-Party bei Mark von ProPublica oder mein Abschiedsumtrunk mit Guardian-Kollegen in einer Manhattener Eckkneipe.
Außerdem habe ich mich sehr darüber gefreut, auf welches Interesse meine Hospitanz hier gestoßen ist. So wurde ich von Bülend Ürük von Newsroom.de und Christian Jakubetz vom Universalcode dazu interviewt.
Gerne hätte ich noch mehr gebloggt, aber leider ist mir da eine ziemlich spannende Stadt dazwischen gekommen. Als nächstes werde ich die Hunderten Bookmarks aufarbeiten und an meinem P5-Projekt weiterarbeiten. Darüber werde ich dann auch wieder hier bloggen.
+++ Donnerstag, 6. Dezember, Datenbanken für Jedermann +++
Ich arbeite derzeit an der Analyse eines riesigen Datensatzes. Es handelt sich dabei um eine CSV-Datei mit mehreren Millionen Zeilen. Mit Excel kann man maximal eine Million Zeilen verarbeiten. Auch Google Spreadsheets ist auf 400.000 Datensätze limitiert. Diese Grenzen erreicht man schneller als man denkt.
Also arbeite ich mit Datenbanken. Das ist zwar nichts Neues, allerdings war mit nicht klar, wie einfach es ist, das alles lokal auf seinem Rechner einzurichten. Es gibt etwa den sehr einfachen Weg, mit nur einem Klick eine MySQL-Datenbank zu installieren. Das Guardian Interactive-Team arbeitet unter anderem mit dem kostenlosen Programm MAMP. Nach der Installation klickt man auf „Server starten“ und schon kann man seine Datensätze importieren und mit dem integrierten Tool PHPMyadmin abfragen starten und darin recherchieren.
Noch besser ist es, seine Daten mit einem Tool wie Sequel Pro zu durchforsten, neu anzuordnen und etwa die wichtigsten Daten für sich oder seine Geschichte zu extrahieren. SQL-Abfragen sind nicht schwer, das Prinzip versteht man schnell. Es gibt viele Tutorials dafür. Immer beachten sollte man im Vorfeld, wie man seine Daten in verschiedene Tabellen aufteilt, atomar hält und die Relationen untereinander festlegt.
Es gibt noch viele weitere Arten von Datenbanken. Die Kollegen von Propublica arbeiten etwa vorwiegend mit PostgreSQL. Einer der Vorteile davon ist die Erweiterung PostGIS, die mit geographischen Objekten umgehen kann, also etwa mit einer einfachen Abfrage den Abstand von einem zu einem anderen Latitude/Longitude-Punkt berechnen und ausgeben kann.
Spricht man von Big Data, also Datensätzen weit über der Millionengrenze, helfen auch diese Tools nicht mehr unbedingt aus. Interessant, um enorm große Datensätze greifbar zu machen ist etwa das Programm Jigsaw. Viele nützliche Tools wie dieses sind allerdings nur im englischsprachigen Raum einsetzbar. Die Arbeitsgruppe Pandaprojekt will das ändern und solche Tools für den deutschsprachigen Raum anpassen. Ich bin dort auch dabei.
+++ Freitag, 30. November, The Guardian +++
Nach etwas mehr als zwei Wochen habe ich am Dienstag meine Hospitanz als P5-Fellow bei Propublica beendet. Ich habe unglaublich viel gelernt bei Scott Klein, Jeff Larrson, Al Shaw und Lena Groeger – über News-Apps-Development und über die Arbeitsweise der Investigativ-Onlinepublikation insgesamt. Bis zum Schluss haben mich die Kollegen bei meinem Projekt unterstützt. So bald wie möglich werde ich darüber mehr berichten.

Das Büro des Guardian US am späten Abend
Seit Mittwoch bin ich nun beim Guardian. Dort arbeite ich im Interactive-Team von Gabriel Dance, Feilding Cage, Julian Burgess und Greg Chen an einem Projekt für Amanda Michel, die das Open-Journalism-Team leitet.
Beim ersten gemeinsamen Mittagessen haben wir uns unter anderm über Wahldaten unterhalten. Zwar waren die Kollegen in den USA außerordentlich kreativ in der Präsentation ihrer interaktiven Anwendungen. Doch hatten alle mit Live-Daten der AP genau die gleiche Quelle. Das könnte sich zur nächsten Wahl ändern, vor allem Google will mitspielen. In diesem Zusammenhang ist vor allem auch das Projekt “Open Elections” zu nennen: “Our goal is to create the first free, comprehensive, standardized, linked set of election data for the United States, including federal and statewide offices.” Sicher ist: Die Online-Berichterstattung kann nur noch besser werden, wenn sich wirklich alle daran beteiligen können, die sich nicht unbedingt die teuren Daten kaufen können.
Auch in Deutschland bereiten sich die Redaktionen langsam aber sicher auf die Bundestagswahl im kommendem Jahr vor. Es könnte ein wichtiger Schritt für den Datenjournalismus werden. Die Wahlkreise gibt es zumindest schon einmal als Shapefiles.
Nicht unerwähnt bleiben sollte eine der außergewöhnlichsten interaktiven Wahlberichterstattungen des Guardian-Interactive-Teams. Das Comic über den Werdegang Mitt Romneys, “America: Elect!“, wurde unter anderem mit dem Tool Skrollr umgesetzt. Entwickler Julian hat ein kleines Making Of dazu auf dem übrigens sehr empfehlenswerten Developer-Blog des Guardian verfasst.
+++ Samstag, 24. November, Alltags-Werkzeug Scraping +++
Propublica setzt sehr stark auf Scraping als wichtiges Recherchetool. Beinahe täglich wird die Frage gestellt: „Can we scrape that?“ Wie selbstverständlich gehen die Reporter dann an ihren Rechnern durch die so gewonnenen Datensätze und suchen nach Geschichten. Informationsbeschaffung auf diesem Weg gehört zum Arbeitsalltag.

Coden in der New York Public Library
Auch wenn ich selbst bereits den ein oder anderen Datensatz gescrapt hatte, habe ich doch im Propublica-Nerdcube sehr viel Neues gelernt. Außerdem lese ich gerade das Buch „Scraping for Journalists“ von Paul Bradshaw. Ich will hier kein Scraping-Tutorial aufschreiben – davon gibt es bereits genügend. Ich will nur kurz ein, zwei Dinge festhalten, die mir selbst neu waren.
Wenn man etwa schnell Hunderte Dateien automatisiert herunterladen will, genügt (zumindest bei Linux und OSX) der Command-Line-Befehl curl –o
curl -o download#1.html http://www.berlin.de/sen/bildung/schulverzeichnis_und_portraets/anwendung/Schulportrait.aspx?IDSchulzweig=[10303-10309]
Will man aber nur bestimmte Teile einer Datei, muss diese geparst werden. Bei Propublica nutzen die Kollegen neben dem bekannten Nokogiri das mir bis dahin unbekannte Rubygem Crack.
In diesem Zuge musste ich mein rudimentäres Vorwissen über Regular Expressions und die Commandline/das Terminal schnell auffrischen. Denn beides sollte man blind beherrschen, wenn man schnell Informationen extrahieren und für die eigenen Zwecke aufbereiten will.
Nicht neu war mit das Tool Wireshark. Aber zum ersten Mal habe ich live gesehen, wie man damit den Netzwerkverkehr abhören kann. So lässt sich etwa analysieren, welche Informationen zwischen Server und Browser hin- und hergeschickt werden. Das wiederum kann dann mit Tools wie dem bereits oben erwähnten Curl (in OSX und Linux integriert) imitiert werden.
+++ Sonntag, 18. November, Open Data +++
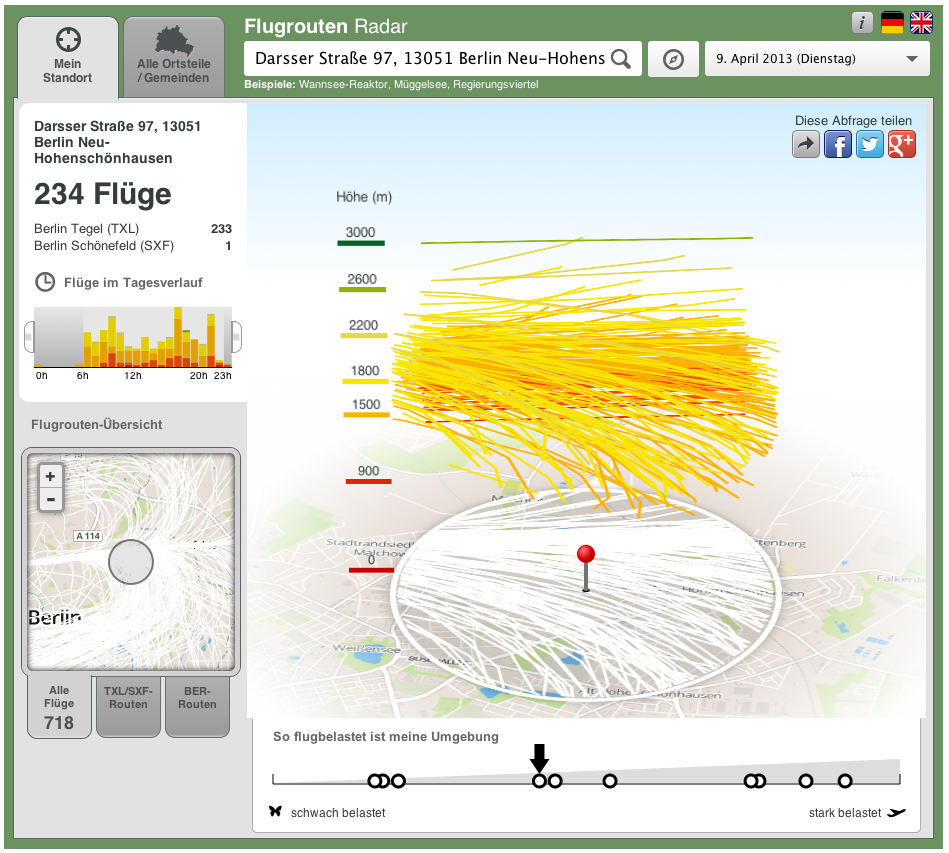
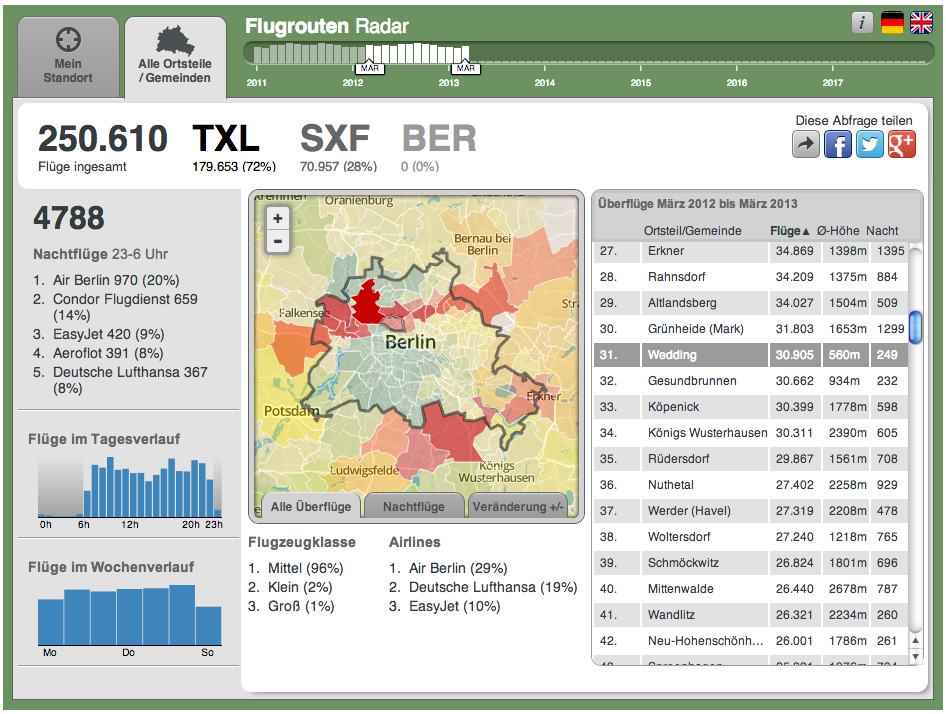
Wenn man in Deutschland mit Geodaten arbeiten will, so bleibt einem häufig nur Openstreetmaps. Berlin bietet seine Ortsteil-Geometrien zwar im KML-Format an, schon bei Brandenburg wird es da schwieriger. Man wird zu einem kostenpflichtigen Angebot verwiesen. In einem Projekt zur Wahl in Berlin mussten wir einzelne Wahlkreise nachzeichnen, weil sie nur als PDF(!) angeboten wurden.

In den USA gibt es eigentlich nichts, was nicht als Shapefile angeboten wird
Diesbezüglich sieht es in den USA deutlich besser aus. Hier bietet das United States Census Bureau alle nur erdenklichen Daten an. Auch veröffentlichen sie selbst interessante Visualisierungen.
Außerdem gibt es bei der Behörde Federal Communications Commission (FCC) eine API zu Geodaten auf die Granularität einzelner Blocks. Die FCC ist sogar auf Github.
Die MTA, die das New Yorker Nahverkehrsnetze betreibt, bietet Live-Verkehrsdaten über eine offene Schnittstelle an. So entstehen wirklich hilfreiche Apps, wie Bustime, die fast live auf einer Karte anzeigt, wo sich der entsprechende Bus gerade befindet. In Berlin habe ich so etwas ähnliches bisher nur auf der Ifa vom Fraunhofer-Institut gesehen. Der VBB hat nun aber erste Datensätze bereitgestellt, die ersten interessanten Anwendungen sollen auf dem entsprechenden Entwicklertag „Apps and the City“ entstehen.
Überhaupt gewährt New York Zugriff auf einen riesigen Datenschatz, wie etwa den Stromverbrauch nach Postleitzahlenbereich.
+++ Donnerstag, 15. November, Nerd-Fellow +++
Meine ersten Arbeitstage bei Propublica waren grandios. Ich wurde herzlich in Empfang genommen. Dann ging es gleich zur Sache.

Ich, arbeitend im Propublica-Nerdcube. Foto: Scott Klein
Die Kollegen arbeiten fast ausschließlich mit Ruby on Rails. Die theoretischen Grundlagen von Rails kannte ich zwar, auch habe ich schon mal einen kleinen Scraper in Ruby geschrieben, aber eigentlich habe ich bisher nur clientseitig mit Javascript gecodet.
Ich musste mich also schnell auf Stand bringen. Dafür haben mich Scott Klein, Jeff Larson, Al Shaw und Lena Groeger schnell mit Screencasts und Tutorials versorgt. Denn keiner von ihnen ist gelernter Programmierer, sie sind alle Quereinsteiger und Autodidakten.
Auch wenn ich mich immer flotter zwischen Command Line, Git und PostGIS bewege, bin ich noch weit entfernt davon, eine News App wie die heute veröffentlichte über Pipelines in den USA selbst in Ruby on Rails zu entwickeln. Aber dafür bin ich hier. Jetzt gehe ich wieder üben.
+++ Sonntag, 11. November, New York +++
Ich bin da. Nach der langen Planung und Vorbereitung habe ich am Freitag dann tatsächlich die erste Nacht in meiner neuen, einmonatigen Wahlheimat, dem New Yorker Stadtteil Williamsburg, verbracht.

Daten säubern am Flughafen. Im Hintergrund mein A380 nach New York.
Die letzte Woche habe ich mein P5-Projekt intensiv vorbereitet, mit den Kollegen von Propublica darüber per Telefonkonferenz diskutiert, mit Fachleuten über das Thema gesprochen, über Datensätze verhandelt, diese gesäubert und erste Visualisierungen und Mockups gebaut – letzteres auch noch während meiner Reise.
Um was es bei meinem Projekt genau geht, möchte ich an dieser Stelle noch nicht verraten, da ich auch für den Propublica-Nerd-Blog darüber bloggen werde.
Hier werde ich aber so oft es geht über Programme, Tools, Workflows und Best-Practice-Beispiele im Umfeld von Programmierung und Journalismus schreiben. Morgen geht’s los. Dann werde ich hier auch regelmäßiger updaten.
+++ Montag, 22. Oktober, künftige Kollegen +++
Das Datenjournalismus-Team von Propublica bloggt unter „The Propublica Nerd Blog“. Dort gibt es viele Tutorials und Tools. Besonders empfehlenswert sind die Beiträge zu Timelines, Adaptive Design und Scraping (1,2). Das Team leitet Scott Klein, durch den der Begriff News Apps geprägt wurde.
Der Guardian hat sich dem „offenen Journalismus“ verschrieben. Was es damit auf sich hat, erklären sie mit ihrem „Three little pigs“-Video. Für die US-Ausgabe des Guardian betreut Amanda Michel Projekte, bei denen Leser vor allem mittels Crowdsourcing und Social Media mit in den journalistischen Prozess eingebunden werden.
Im selben Büro sitzt auch das Guardian US interactive team um Gabriel Dance, den ich bereits 2010 in New York kennenlernte. Damals arbeitete er noch bei der New York Times und führte mich durch den Newsroom in der 8th Avenue. Von ihm stammen unter anderem isbarackobamathepresident.com und „Gay rights in the US“.
 Follow
Follow








")























