Vor und nach der Bundestagswahl 2013 hat die Berliner Morgenpost einige reine Online-Formate veröffentlicht. Wir haben dabei wieder mit Tools und Web-Techniken experimentiert. Wir wollen das, was wir dabei gelernt haben, teilen – und veröffentlichten daher an dieser Stelle Werkstattberichte und Tutorials.
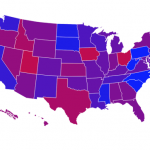
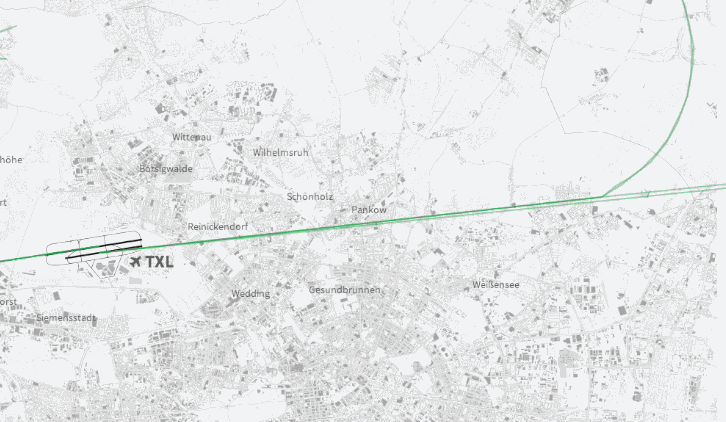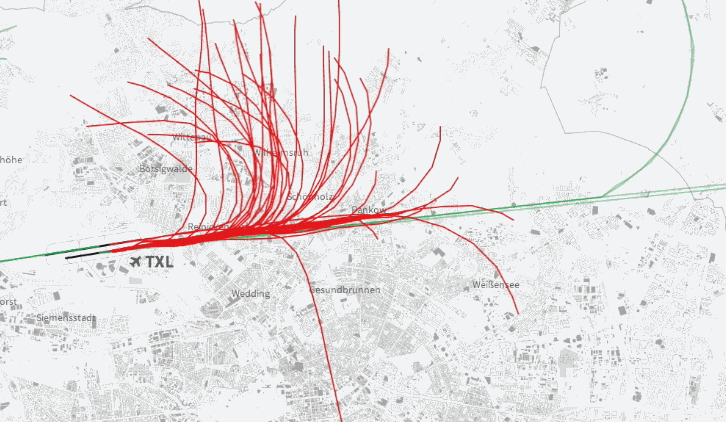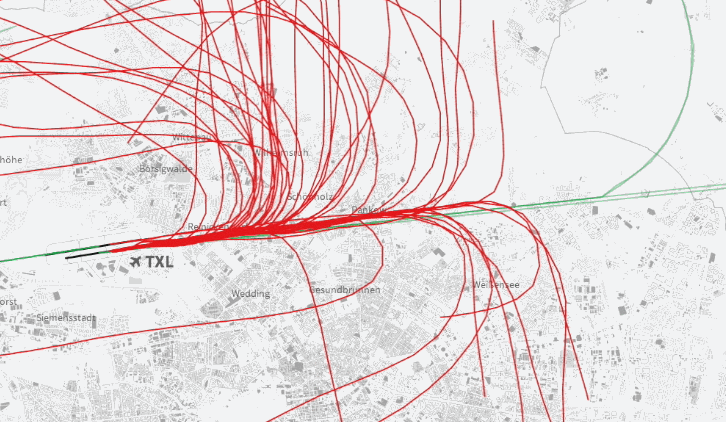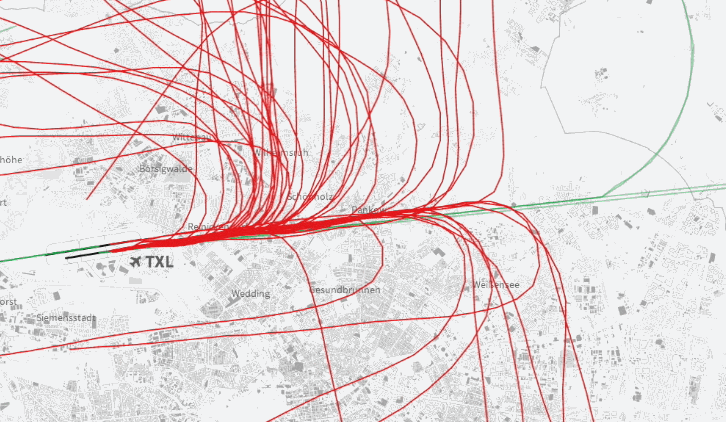
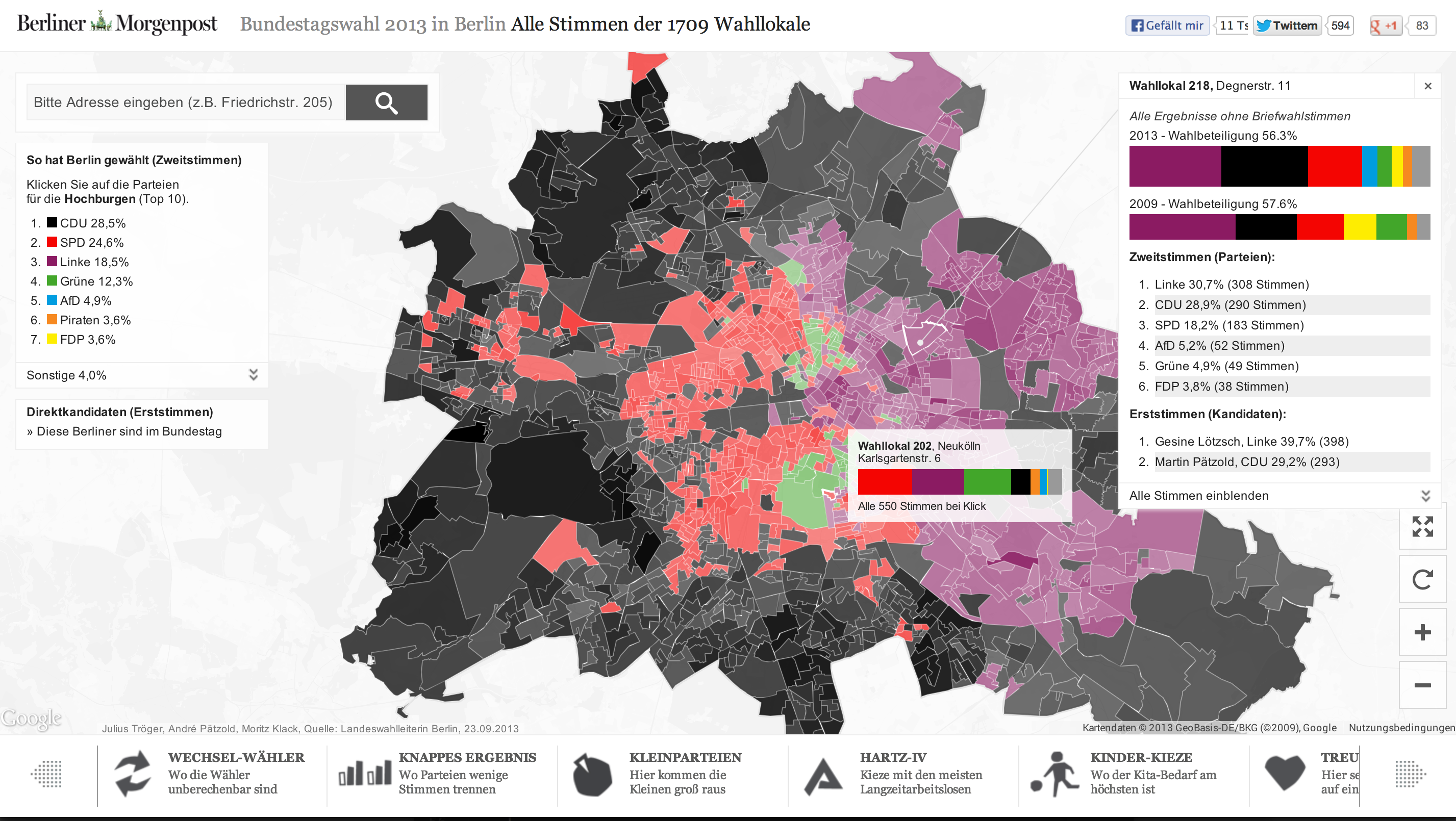
23.09.2013: Berlinwahlkarte 2013 – Alle Ergebnisse der 1709 Berliner Wahllokale
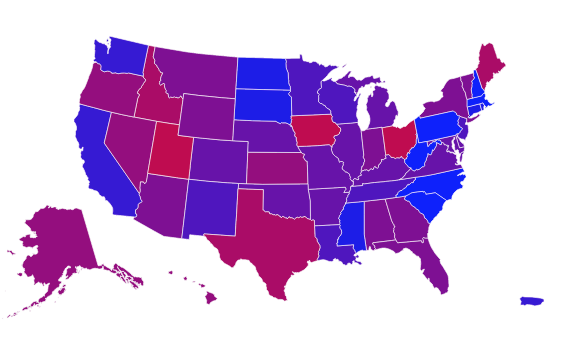
Nach unserer interaktiven Karte zur Berliner Abgeordnetenhauswahl 2011 haben wir (André Pätzold und Julius Tröger) zur Bundestagswahl 2013 eine Neuauflage unter berlinwahlkarte2013.morgenpost.de erstellt. Wir haben aus unserer ersten Berlinwahlkarte gelernt und unsere 2013-Version rundumerneuert. Das wurde unter anderem möglich, weil Web-Entwickler Moritz Klack unser kleines Team verstärkte und maßgeblich am Erfolg der Karte beteiligt war.
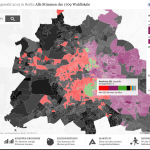
Gewinner, Verlierer, Statistiken: Unsere Karte mit allen Wahllokal-Ergebnissen
Zwei Tage nach der Wahl dürfen wir uns über mehr als 14.000 Facebook-Likes, unzählige Tweets und überwältigende Zugriffe freuen. Vor allem die immer noch vorhandene Teilung Berlins beim Wahlverhalten war für viele neu und ein großes Thema in Tweets aus den unterschiedlichsten Ländern.
Die neue Karte zeigt wieder jede in den Berliner Wahllokalen abgegebenen Erst- und Zweitstimme. Und das in der im deutschen Wahlrecht kleinstmöglichen und somit detailliertesten Einheit, der Stimmbezirksebene. Sie zeigt tatsächlich nur, wie in den 1709 Berliner Wahllokalen am Sonntag abgestimmt wurde. Die Daten dazu kamen gegen 3 Uhr in der Wahlnacht. Vor allem bei der Wahlbeteiligung ergeben sich so sehr niedrige Werte. Wir haben uns für diese Darstellung entschieden, da wir so die Ergebnisse sehr detailliert auf Kiezebene zeigen können. Briefwahlbezirke (568) sind deutlich gröber gefasst, die Briefwahlstimmen lassen sich nicht einfach auf die Wahllokale verteilen. Wir arbeiten jedoch an einer Darstellung, bei der die Briefwähler zum endgültigen Ergebnis zusätzlich berücksichtigt werden. (Werden wir in dieser Wahlkarte doch nicht mehr umsetzen.)
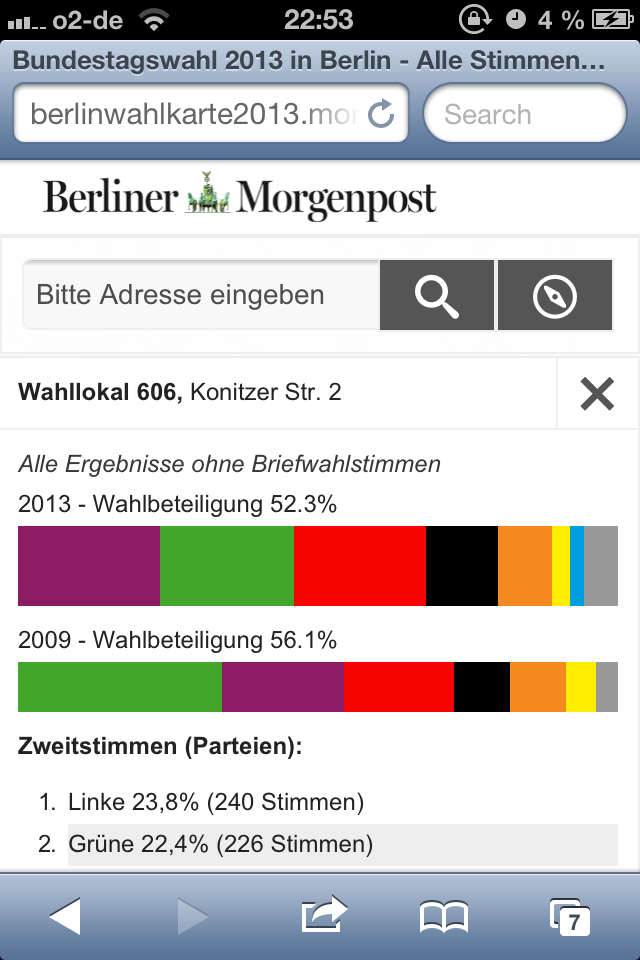
Responsiv-Konzept: Nur das nötigste
Darüber hinaus zeigen wir die Hochburgen der Parteien und statistische Auswertungen aus eigenen Abfragen („Wo die Wechselwähler leben“) und Wahlstrukturdaten („Wo die ältesten leben“).
Außerdem ermöglichen wir mit Deep-Links jeden Zustand der Karte zu teilen und somit etwa in den Texten unserer Wahl-Nachberichterstattung direkt auf einzelne Aspekte der Karte einzugehen.
Des Weiteren ist die Karte diesmal nicht in unser Standard-Layout gepresst, sondern für eine Vollbild-Ansicht optimiert. Sie passt sich responsiv an alle Bildschirmgrößen an. So kann sie sowohl auf Tablets optimal betrachtet werden, als auch auf großen Monitoren, wo die Karte voll zur Geltung kommt.
Weniger Google – mehr QGIS und GDAL
Die 2011er-Version haben wir noch vorwiegend mit Google-Tools wie Fusion Tables und Charts umgesetzt. Das lag vor allem am mangelnden Programmier-Verständnis. Dieses Jahr nutzen wir zwar noch die Google-Karte und den –Geocoder (der kostenlos ist, aber nur für Google-Karten). Fusion Tables setzen wir aber nur noch an einer Stelle ein: Mit der SQL-Api und der Methode ST_INTERSECTS kann man nämlich herausfinden, ob ein Punkt in einem Polygon liegt. So steuern wir etwa die Stimmbezirk-Zuordnung, nachdem Nutzer ihre Adresse eingeben.
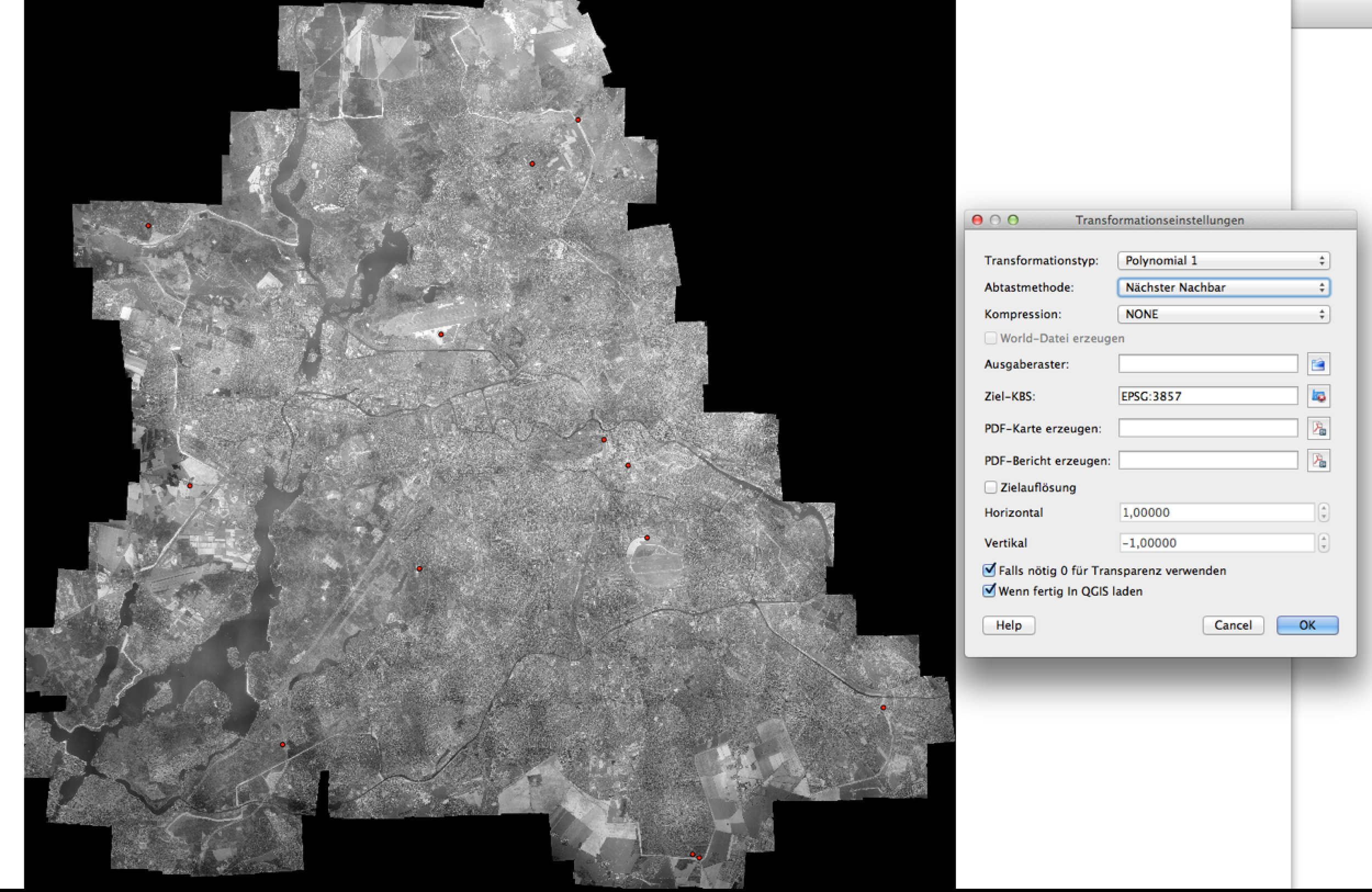
Shape-Umwandlung mit QGIS
Im Gegensatz zu 2011 konnten wir dieses Jahr unter ganz anderen Voraussetzungen arbeiten. Nicht nur war Web-Entwickler Moritz Klack an Bord. Die Berliner Landeswahlleiterin stellte uns diesmal auch ein Shapefile bereit, das Polygone für jeden der 1709 Stimmbezirke enthält – 2011 mussten wir die Wahlkreise noch von Hand nachzeichnen. Das Shapefile enthält neben den Stimmbezirken auch die Wahlbezirke. Um diese daraus zu extrahieren, haben wir die hervorragende Software Quantum GIS (QGIS) eingesetzt. QGIS ist gerade in der Version 2.0 erschienen.

Shape-Vereinfachung: Hinten: Original. Vorne: Punkte halbiert
Die von uns gewählte, detaillierte Darstellung bereitete uns aber auch Probleme, da das Original-Shapefile aus beinahe 100.000 Geo-Koordinaten besteht. Zwar waren die Stimmbezirke so auf den Meter genau, die Performance der Karte litt aber deutlich. Deshalb mussten wir die Polygone vereinfachen. Um Geoformate umzuwandeln kann GDAL (für Mac am besten GDAL_Complete bei KyngChaos downloaden) etwa mit dem ogr2ogr-Befehl im Terminal eingesetzt werden. In unserem Fall nutzten wir den Befehl „ogr2ogr output.shp input.shp -simplify 7“. So konnten wir die Punkte in unserem Shapefile nach einigem hin- und herprobieren ohne wirklich sichtbare Qualitätseinbußen mehr als halbieren und die Geschwindigkeit der Karte deutlich steigern. (Siehe Update weiter unten!)
Probleme hatten wir auch mit Apple-Produkten: Kurz vor der Veröffentlichung der Karte launchte Apple iOS 7. Nach ersten Tests unserer Karte mit dem neuen Betriebssystem wurde schnell klar, dass die neuste Safari Version offensichtlich starke Probleme mit intensiven Javascript-Applikationen hat. Die Erstellung der 1709 Polygone der Stimmbezirke brachte den neuen Browser zum abstürzen. Auf alten iOS-Versionen funktioniert das hingegen problemlos. Der neue Safari hat tatsächlich noch einige Bugs, die das Nutzen vieler aktueller Technologien unmöglich machen. Wir mussten für iOS-7-Nutzer also eine Fallback-Variante erstellen, die die Nutzung etwas einschränkt.
Tools für die Arbeit mit (Geo-)Daten
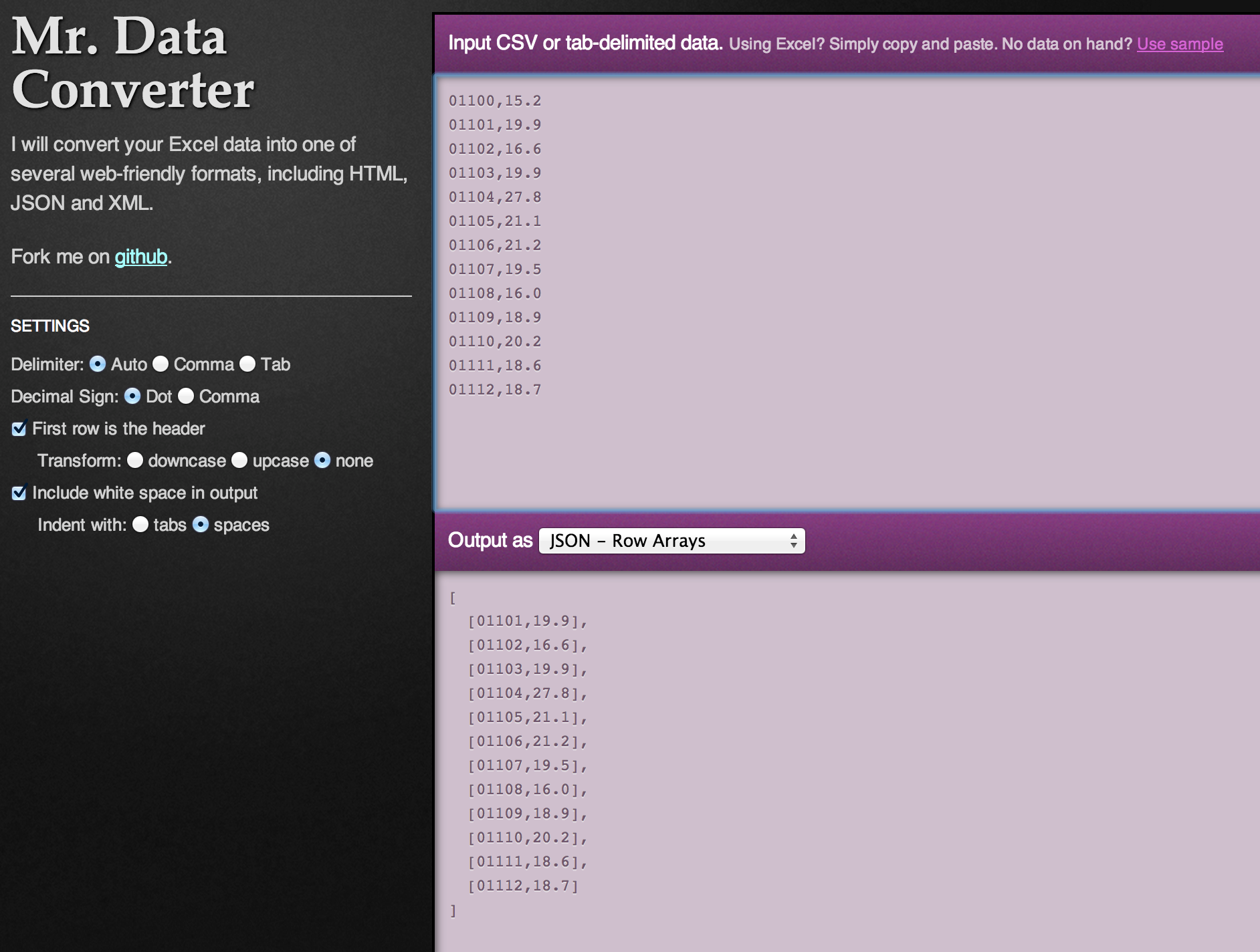
Neben QGIS und GDAL kamen für die Berlinwahlkarte weitere Tools wie Shape Escape (Import von Shapefiles zu Fusion Tables), CartoDB (Export in verschiedene Datenformate), GeoJSON.io (Einfache Bearbeitung von Geodaten) sowie Mr. Data Converter und Open Refine (Umwandlung von Tabellen in JSON-Format) zum Einsatz. Viele Daten, etwa die jeweiligen Partei-Hochburgen, haben wir direkt in den Quellcode geschrieben werden in kleinen Datenhappen nachgeladen um Ladezeiten zu vermeiden. Kartentools wie Leaflet, Mapbox, Tilemill, Stamen und TopoJSON kamen diesmal nicht zum Einsatz, wollen wir uns aber für künftige Projekte genauer ansehen.
Excel zu JSON: Tool: Mr. Data Converter
Weil wir viel mit Geodaten hantierten, bekamen wir auch ein Grundverständnis von Karten-Projektionen. Geodaten bestehen grundsätzlich aus einer Menge von Koordinatenpaaren. Da die Erde eine Kugel ist, wir aber mit flachen Karten arbeiten, muss jeder Punkt auf der Erde daher umgerechnet werden. Dafür gibt es etliche Bezugssysteme. Der Quasi-Standard, den etwa Open Street Maps oder Google nutzen, ist die Web-Mercator-Projektion (EPSG: 3857, WGS84). Wenn man also ein Shapefile bekommt, sollte als erstes die richtige Projektion sichergestellt werden. Hatten wir Fragen, wurde uns immer unter gis.stackexchange.com sehr schnell weitergeholfen.
Mischung aus Abstrakt- und Detaildarstellung
Beispiel SVG-Karte ohne Details
Immer wieder wird darüber debattiert, ob man detaillierte Karten mit Straßenverläufen, Flüssen etc. oder eher abstrakte Darstellungen wie etwa lediglich mit Umrissen der Ortsgrenzen (z.B. SVG-Darstellung bei ) verwenden soll. Wir sind der Meinung, und das hat sich nach zahlreichen Tests unserer Berlinwahlkarte bestätigt, dass sich Nutzer sehr wohl an Straßen, Flüssen, Parks orientieren, um ihr Haus zu finden. Aber nur in einer nahen Zoomstufe. Als Übersicht sind Straße und Co. tatsächlich eher störend. Wir haben uns also entschieden, den Kartenstil je nach Zoomstufe anzupassen. Allgemein haben wir in Sachen Usability immer die Heuristiken von Molich und Nielsen im Blick gehabt, und versucht, möglichst viel davon umzusetzen (Konsistenz, sofortiges Feedback auf Nutzereingaben, „Less is more“) .
Update/Ergänzung 16.10.2013:
Wir haben ein Update der Karte eingespielt. Einerseits haben wir nun die endgültigen Wahlergebnisse eingepflegt und kleine Bugs behoben (z.B. „.“ statt „,“ bei manchen Dezimalzahlen). Andererseits haben wir aber die Hinweise von Jeremy Stucki und Ralph Straumann aufgegriffen und die Polygone der Stimmbezirke neu umgerechnet und hochgeladen.
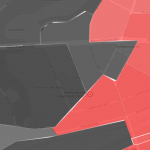
Fehlerhafte Topologie nach GDAL Simplify
Wie im Blogpost oben beschrieben, mussten wir die 1709 Polygone der Stimmbezirke vereinfachen, da es bei den vielen Tausend Punkten zu Performance-Problemen kam. Wir haben die Anzahl der Punkte also mit einem GDAL-Befehl halbiert. Das funktionierte soweit auch super. Allerdings wurde so die Topologie zerstört, in großen Zoomstufen konnte man Lücken oder Überlappungen zwischen den Stimmbezirken erkennen. Für uns war das ein notwendiges Übel und beschlossen daher, das so umzusetzen.
Die beiden Geo-Experten Jeremy Stucki und Ralph Straumann hatten uns allerdings direkt nach der Veröffentlichung des Blogbeitrags darauf hingewiesen, dass das viel besser geht. Vielen Dank an dieser Stelle noch einmal für die Hilfe – das zeigt einmal mehr, wie sich die Datenjournalismus-Community gegenseitig hilft. Nach Rücksprache möchte ich natürlich auch hier teilen, was Jeremy per Mail schrieb:
„Da du ja GDAL schon installiert hast, ist das einzige, was du noch brauchst Node.js. Am einfachsten installierst du TopoJSON dann übers Terminal:
npm install -g topojson
Und dann wandelst du ein Shapefile so um:
topojson -p –simplify 2e-9 — in.shp > out-topo.json
Der -p Parameter stellt sicher, dass die Attribute (Name, Nummer etc.) mitkopiert werden, –simplify gibt an wie stark du vereinfachen willst, d.h. die Flächengenauigkeit in Steradianten. 2e-9 ist der Wert, den ich für die Schweiz verwende, das kannst du also eher ein bisschen grösser wählen, da musst du etwas experimentieren. Als Alternative kannst du auch –simplify-proportion angeben, damit bestimmst du einfach, wie viele Punkte du schliesslich haben willst. 50% der Ausgangspunkte ist also –simplify-proportion 0.5.
Es gibt noch viel mehr Optionen, nachzulesen unter https://github.com/mbostock/topojson/wiki/Command-Line-Reference
Um dann wieder ein GeoJSON zu kriegen:
geojson –precision 3 -o out-verzeichnis — in-topo.json

Beispiel mit precision 3: Für Berlin-Details zu gering
in-topo.json ist dabei die TopoJSON-Datei, die du vorher erstellt hast. –precision gibt dabei an, wie viele Nachkommastellen du in deinen GeoJSON-Koordinaten haben willst. Je weniger, desto ungenauer, aber kleiner die Datei. -o gibt das Verzeichnis an, wo das GeoJSON erstellt wird (oder werden, weil eine TopoJSON-Datei auch mehrere Layer beinhalten kann).“
Nach einigem hin- und herprobieren rechneten wir die 1709 Stimmbezirks-Polygone als TopoJSON mit simplify-proportion 0.5 und als GeoJSON wiederum mit precision 4 heraus. Vor allem bei letzterem sind drei Koordinaten-Nachkommastellen für die detaillierten, kleinen Polygone zu grob. Das Endergebnis kann sich nun wirklich sehen lassen. Für eine GeoJSON-Datei, die gerade einmal 644KB groß ist, ist der Detailgrad immer noch ausreichend hoch und die Topologie bleibt erhalten.
13.09.2013: Scrollbare Infografik – die Berliner Parteien in Zahlen
In der Printausgabe der Berliner Morgenpost haben wir (Christian Schlippes, Karin Sturm, Joachim Fahrun und Julius Tröger) zwischen dem 9. und 14. September sechs ganzseitige Infografiken veröffentlicht. Sie zeigen für Berlin relevante Zahlen der sechs Parteien, die derzeit im Deutschen Bundestag oder im Berliner Abgeordnetenhaus sitzen, CDU, Linke, SPD, Grüne, Piraten und FDP. Welche Partei verliert am meisten Mitglieder – welche gewinnt wie viele hinzu? Wer wählt die Parteien? Wie viel steht zu den wichtigen Berliner Themen in den Wahlprogrammen? Wie hoch sind die Wahlkampfbudgets? Die Grafiken geben Antworten auf diese und weitere Fragen.

Scroll-Infografik – Die Berliner Parteien in Zahlen
Am letzten Tag der Serie veröffentlichten wir diese Grafiken auch online. Allerdings nicht 1:1. Wir stellen sie in einer aufwendigen, scrollbaren, animierten Infografik dar. Wir entschieden uns dafür, weil die komplexe Datenvisualisierung dadurch in kleinere Aufmerksamkeits-Abschnitte unterteilt werden kann. Im Gegensatz zur Zeitungsversion ist es dabei auch möglich, die Parteien untereinander zu verglichen.
Technisch kamen dabei keine Scroll-Bibliotheken wie Skrollr, Supercrollorama oder Stellar.js zum Einsatz. Deren Schnittstellen waren für unseren speziellen Fall nicht ausreichend. Interaction-Designer und Programmierer Markus Kison ließ sich per Javascript einfach die Stelle ausgeben, bis zu der der Nutzer jeweils scrollte. Aufgrund dieses Wertes wurden dann zwischen bestimmten Fixpunkten Animationen abgespielt. Da die Grafiken bereits in Form von Illustrator-Dateien vorlagen, wurden sie auch nicht komplett in SVG-Vektorgrafiken umgebaut, sondern teils als fertig GIF-Datei in den Hintergrund gelegt. An sinnvollen Stellen wurden dann SVG-Animationen mit Hilfe von D3 eingesetzt.
Einen Großteil der Zeit verbrachten wir am Ende mit dem Finetuning des Grafik-Verlaufs. Es stellte sich als größte Herausforderung heraus, einerseits den Spannungsbogen aufrecht zu erhalten, die Aufmerksamkeit immer auf das wichtigste Element zu lenken und allgemein einen stimmigen Scroll-Ablauf zu schaffen. Man sollte sich bei dieser Art von Infografik frühstmöglich ein Storyboard zurechtlegen.
Interessante Scroll-Grafiken kommen auch immer wieder vom Interactive-Team des Guardian US. Besonders eindrucksvoll ist ihr Jahresrückblick „2012 in America“, durch den man sich nur mit dem Mausrad/Touchpad bewegen kann.
02.09.2013: Interaktiver Stimmzettel – Welche 150 Kandidaten in Berlin zur Wahl stehen
Bei der Bundestagswahl 2013 stehen 150 Direktkandidaten in zwölf Berliner Wahlkreisen zur Wahl. Dabei können alle Berliner zwar denselben 17 Parteien ihre Zweitstimme geben. Die Kandidaten für die Erststimmen sind aber in jedem Wahlkreis unterschiedlich.

Vorab-Stimmzettel für Berlin
Jede Wahl, ob per Brief oder an der Wahlurne, wird mit zwei Kreuzen auf einem vorgegebenen Stimmzettel durchgeführt. Wir (André Pätzold, Anett Seidler, Moritz Klack und Julius Tröger) haben unseren Berliner Nutzern jeweils ihre persönlichen Zettel vorab originalgetreu nachgebaut und mit Zusatzinformationen (Fotos, Kontaktdaten, Themencheck) zu den Kandidaten und Parteien versehen.
Dabei erläutern wir auch Hintergründe wie etwa die Partei-Reihenfolge auf dem Stimmzettel. Die Linke steht nämlich nur deshalb vor der SPD, weil sie bei der Bundestagswahl 2009 exakt 579 Zweitstimmen mehr hatte. Darüber hinaus zeigen wir weitere Details wie die Vorjahresergebnisse in den jeweiligen Wahlkreisen und soziodemographische Daten der Kandidaten. Interessant ist dabei zum Beispiel, dass im Wahlkreis 76 (Pankow) keine einzige Frau als Direktkandidatin antritt. Da es bei der Wahl schließlich nicht nur um die Personen, sondern vor allem auch um Themen geht, haben wir den Kandidaten-Check von Abgeordnetenwatch integriert.
Die Kandidaten-Fotos erhielten wir auf Anfrage direkt bei den Pressestellen der Parteien. Der Stimmzettel wurde mit HTML, Javascript und CSS umgesetzt. Die Navigationskarte wurde als SVG integriert, die Karte mit den Kandidaten-Geburtsorten per Google-Maps-API. Der Stimmzettel ist auf der Startseite der Berliner Morgenpost prominent platziert. Der Artikel-Teaser soll dort bis 18 Uhr am Wahlabend stehen bleiben. Alle Stimmzettel sind per Deeplink teilbar. Eine Auswahl:
30.08.2013: Animated Gifs – die Gesten der Kanzlerkandidaten analysiert
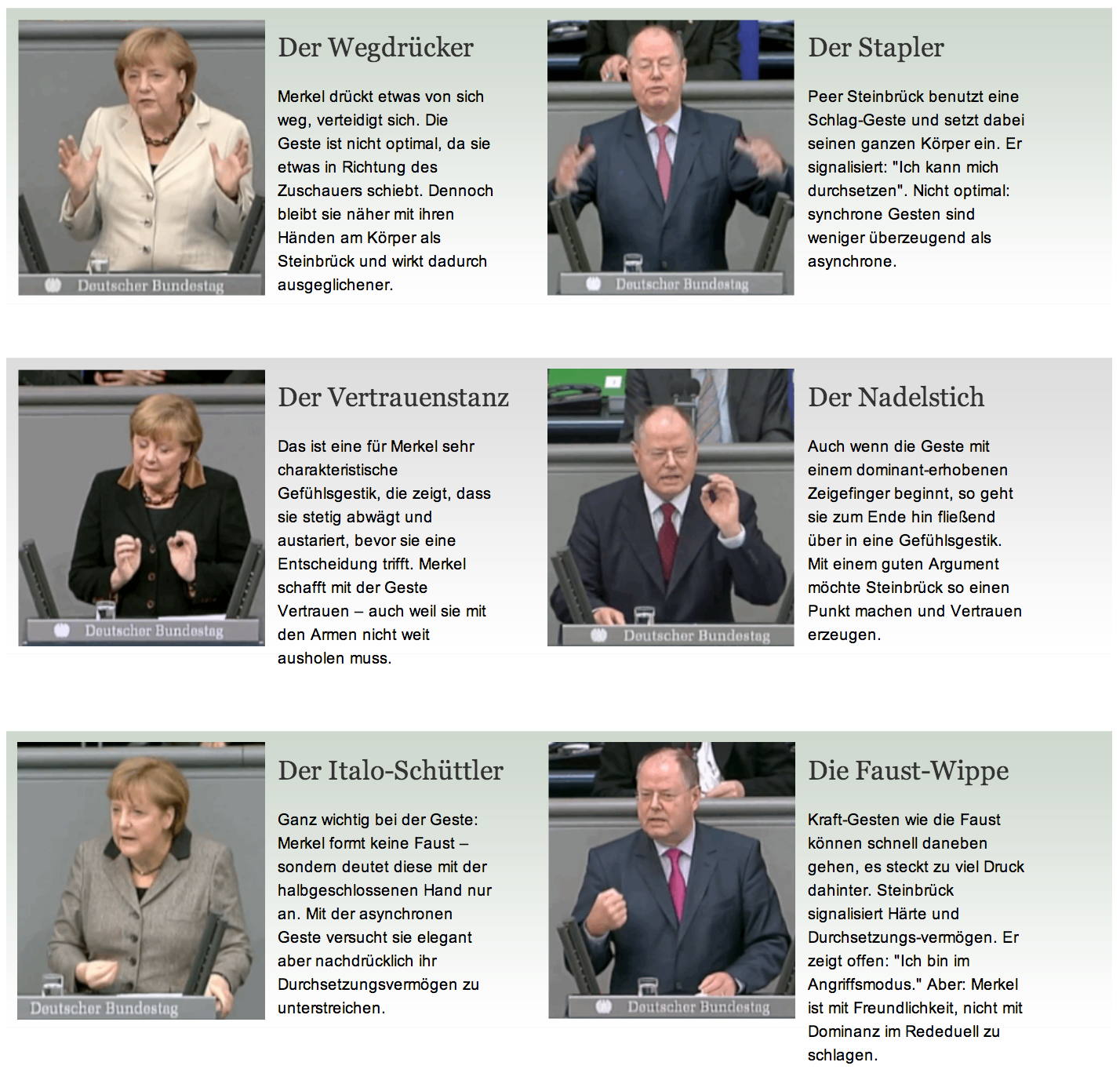
Den Auftakt zu unseren Online-Only-Wahl-Geschichten machte die Analyse zu den Gesten von Angela Merkel und Peer Steinbrück im Vorfeld des TV-Duells. In Form von animierten Gifs haben wir je fünf Gesten der beiden Politiker gegenübergestellt und von Peter Ditko, dem Chef der Deutschen Rednerschule, analysieren lassen. Kollege Max Boenke und ich haben uns sehr über die überaus positive Resonanz gefreut.
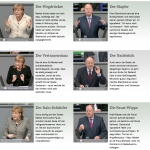
Die Gesten von Angela Merkel und Peer Steinbrück – als animierte Gifs
Das Rohmaterial der Reden von Merkel und Steinbrück haben wir aus der Mediathek des Parlamentsfernsehens des Deutschen Bundestages heruntergeladen. Es darf mit Quellenverweis genutzt werden.
Die jeweils rund 20 bis 30 Minuten lange Reden haben wir in Final Cut Pro X auf entsprechende Gesten gesichtet, geschnitten und als MP4-Dateien exportiert. Diese kurzen Clips haben wir dann mit Gif Brewery (z.B. 4,49 Euro im Apple App Store) in animierte Gifs umgewandelt. Mit einem kleinen HTML– und CSS-Grundgerüst haben wir die Gifs und Texte dann in unser CMS integriert.
Im ersten Schritt werden Start- und Endpunkt des Clips ausgewählt (das Zuschneiden vorab erleichtert diesen Schritt – zudem überfordert man Gif Brewery nicht mit einer zu großen Ausgangsdatei). Unter „Properties“ wird der „frame count“, also die Bilder pro Sekunde, und der „frame delay“ eingestellt. Damit die Gifs flüssig abspielen, haben wir uns für die vollen 25 Frames pro Sekunde entschieden. Viele animierten Gifs im Netz laufen aber auch schon mit rund 15 fps halbwegs flüssig. Den „frame delay“ haben wir mit 100 ms festgelegt.
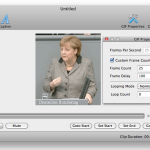
Gifs erstellen mit Gif Brewery
Für die weitere Bildbearbeitung sind zwei Schritte nötig: croppen (beschneiden) und re-sizen (Größe anpassen). Zuerst wird ein Bildausschnitt gewählt und gecropt, dann wird das Bild durch eine manuelle Eingabe von Höhe und Breite in Pixel heruntergerechnet. In unserem Fall sind so Gifs mit einer Breite von 210 Pixeln und einer Größe von etwa 500 Kilobyte entstanden.
Genau darin liegt aber auch das Problem von Animated Gifs. Sie werden zwar in jedem Browser ohne Plugin nativ dargestellt (im Gegensatz etwa zu Flash-Videos). Sind benötigen aber viel zu viel Speicherplatz. Das so genannte Graphics Interchange Format ist nämlich lediglich ein Bildformat mit verlustfreier Kompression. Die Dateien sind also viel größer als etwa JPEG-Bild-Dateien oder H.264-Video-Dateien, die mit verlustbehafteter Kompression arbeiten.
Die New York Times etwa hat auch schon einige Male mit kurzen, geloopten Videosequenzen in Artikeln experimentiert. Sie zeigen statt Animated Gifs aber einfach normale Videos, die sie per HTML5-Videotag mit autoplay und abgeschalteten controls abspielen. Diese Videos sind deutlich kleiner und laden schneller. Allerdings müssen HTML5-Videos in mehreren Dateiformaten exportiert werden, da nicht alle Browser alle Videoformate abspielen. Dieser Aufwand war uns zu groß, da wir nur drei Tage Zeit hatten. Außerdem hält sich die Größe bei den rund zweisekündigen Clips noch in Grenzen. Wir haben uns daher für „richtige“ animierte Gifs entschieden.

 Follow
Follow


















")























