 Follow
FollowWenn wir Informationen zu Nachtflügen, Flugrouten oder Fluglärm brauchen, müssen wir jetzt nicht mehr immer tagelang auf Antworten von Behördensprechern warten. Wir interviewen einfach unsere eigene Datenbank. Mit dem Flugrouten-Radar haben wir uns also eine eigene, täglich aktualisierte Nachrichtenquelle geschaffen.
Mehr als eine halbe Million Flüge und viele Millionen Flugspuren befinden sich hinter unserer neuen News App. Mit den richtigen Datenbank-Queries kommen wir dadurch an Zahlen, die in keiner anderen Statistik auftauchen. Und obwohl das Thema von Redaktionen in Berlin wie kaum ein anderes bearbeitet wird, finden wir so neue Geschichten, wie etwa die über Hunderte Leerflüge zwischen den Berliner Flughäfen.
Flugrouten, Fluglärm, Nachtflüge
Nach der mehrfach geplatzten Eröffnung des Hauptstadtflughafens BER ist es in Berlin zu einer besonderen Situation gekommen: Über den Flughafen Tegel, der eigentlich bereits seit Juni 2012 geschlossen sein sollte, müssen die eigentlich für den BER geplanten Flüge zusätzlich abgewickelt werden.
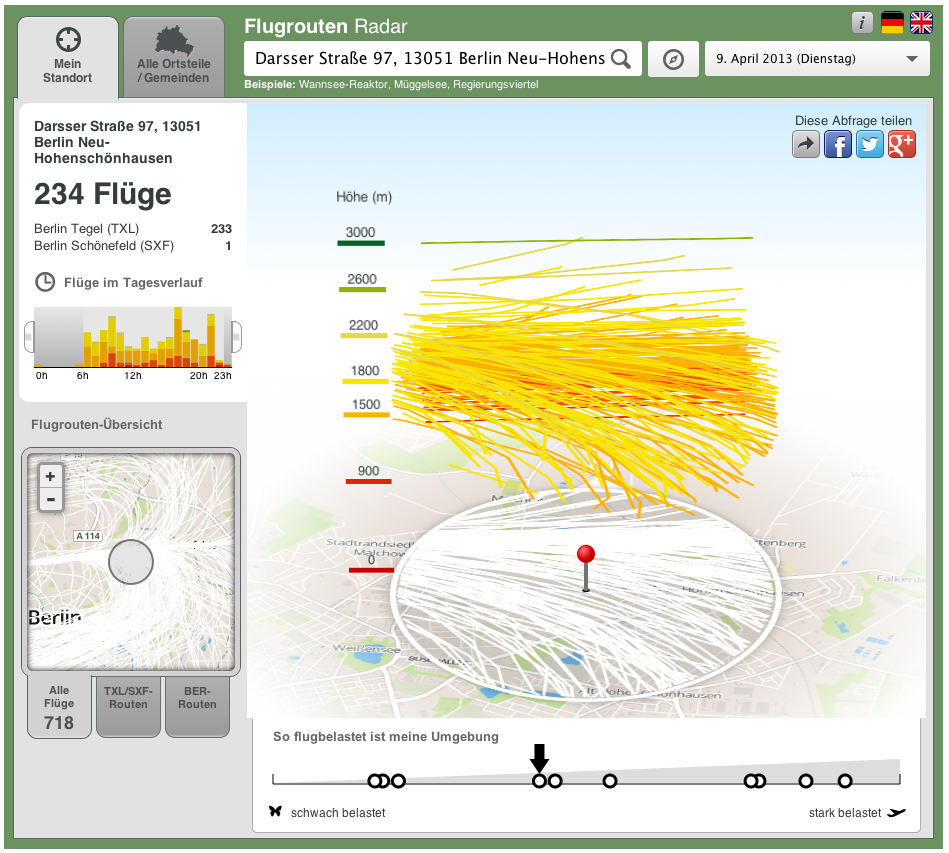
3-D-Ansicht der Flüge über Berlin und Brandenburg
Statt leiser wurde es für die Anwohner in den Einflugschneisen also lauter. Beschwerden über steigenden Fluglärm, Routenabweichungen und Nachtflüge nehmen zu. Debatten über diese Themen waren dabei häufig von Vermutungen geprägt. Genaue Zahlen zu Randzeit- und Nachtflügen sind schwer zu bekommen. Offiziell heißt es etwa: „Nachfragen nach belastenden Störungen [bei Flügen nach 23 Uhr] sind bei der Luftfahrtbehörde grundsätzlich möglich, erfordern dort aber einen erheblichen Recherche-Aufwand.“
Mit dem Flugrouten-Radar wollen wir Betroffenen und Interessierten in der emotional aufgeladenen Debatte ihre ganz persönliche Faktenbasis bieten – täglich aktualisiert und mit automatisierter Analysefunktion. Und wir wollen Daten so verständlich, transparent und personalisiert wie möglich darstellen.
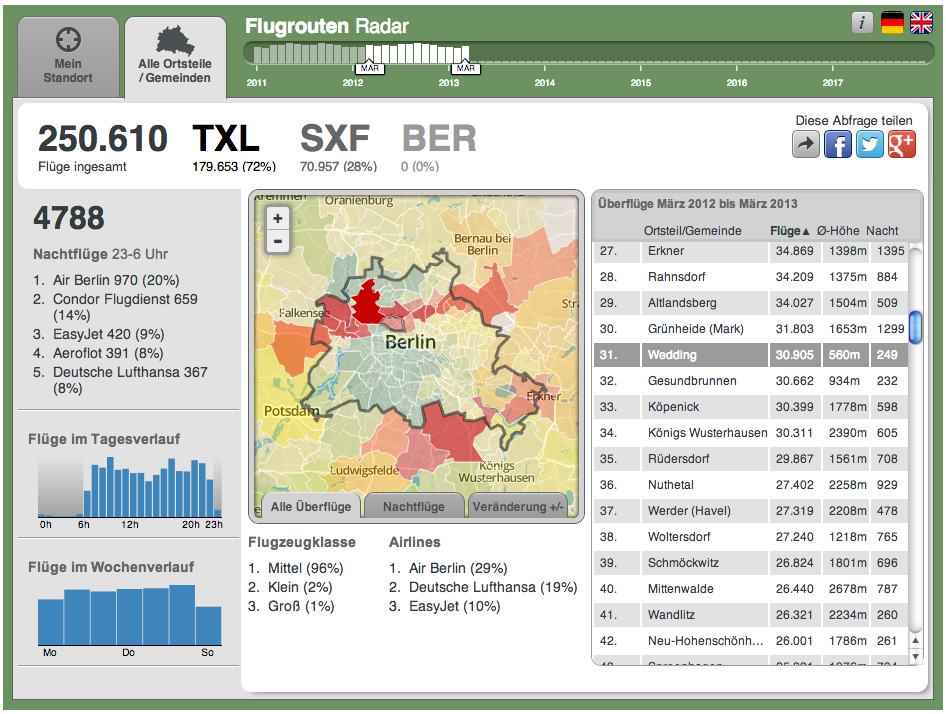
Statistik-Ansicht: Nachtflüge, Airlines, Ortsteile
Einerseits zeigt die interaktive Anwendung erstmals Flughöhen, -zeiten und Flugzeugtypen mit Lärmberechnungen für alle Flüge über einem individuellen Standort in einer dreidimensionalen Ansicht. Andererseits gibt es exklusive Statistiken auf Basis von mehr als einer halben Million Flügen seit Januar 2011, wie sich die Fluglast auf die einzelnen Ortsteile bzw. Gemeinden der Hauptstadtregion über die Zeit verteilt.
Von der ersten Idee bis zur Veröffentlichung des Flugrouten-Radars verging ungefähr ein halbes Jahr. Die Redaktion der Berliner Morgenpost hat dabei mit dem Deutschen Fluglärmdienst (DFLD), dem Datenjournalismus-Team der US-Investigativredaktion ProPublica und der Agentur Kreuzwerker GmbH zusammengearbeitet.
Recherche der Daten
Einen Großteil der Zeit benötigten wir, Julius Tröger und André Pätzold, für die Recherche der Flugspur-Rohdaten. Die gibt es in Deutschland nämlich nicht öffentlich – im Gegensatz zu den USA und Kanada etwa. Dort werden Radardaten aller Flüge per Feed angeboten. Die Deutsche Flugsicherung (DFS) gibt ihre Rohdaten dagegen nicht frei. Entsprechende Anfragen unsererseits wurden abgelehnt. Die DFS veröffentlicht die Daten zwar in ihrer Online-Anwendung „Stanly-Track“ – allerdings nur 14 Tage rückwirkend. Zu wenig für uns, da wir für Vergleiche die Zahlen aus den entsprechenden Vorjahreszeiträumen benötigten.

Unser Testgerät: AirNav RadarBox 3D
Ein anderer Weg an Flugspur-Daten zu gelangen sind so genannte ADS-B-Transponder in Flugzeugen. Die kann man in Deutschland legal mit entsprechenden Receivern wie Mode-S Beast, Transponder-Mouse oder Airnav Radarbox (ab rund 200 Euro bei eBay) empfangen. Live-Flugkarten wie Flightradar24 oder Metafly nutzen diese Technik. Nach einigen Tests entschieden wir uns allerdings gegen diese Variante. Es sind erst rund 70 Prozent der Flugzeuge mit ADS-B-Transpondern ausgestattet. Für detaillierte Analysen wäre das zu wenig.
Auch konnten wir die gewünschten Daten nicht über kostenpflichtige APIs wie Flightstats oder Flightaware bekommen.
Kooperation mit Deutschem Fluglärmdienst
Der DFLD archiviert Flugspuren in der Nähe großer Flughäfen in Deutschland. Diese können auf deren Webseite zudem mehrere Jahre rückwirkend angezeigt werden – mit einer Erfassung von mehr als 96 Prozent. Routen können auf einer statischen Karte oder auf Google Maps bzw. Earth angesehen werden. Die Daten kann man dort auch im Keyhole Markup Language (KML)-Format herunterladen.

Lat, Lng, dB(A): Flugspur-Daten eines Air-Berlin-Flugs
Nach mehreren E-Mails, Telefonaten und Teamviewer-Sitzungen mit Technik und Vorstand des Vereins einigten wir uns auf eine Zusammenarbeit. Wir bekamen die Flugspur-Daten mit Lärmberechnungen nach dem offiziellen AzB-Standard kostenlos im deutlich schlankeren CSV-Format geliefert – rückwirkend und täglich aktuell. Im Gegenzug verweisen wir in unserer Anwendung an mehreren Stellen auf das entsprechende Angebot des DFLD.
Die Datenqualität war von Anfang an sehr hoch. Sie wurde uns auch in Gesprächen mit Experten des Deutschen Luft- und Raumfahrtzentrums sowie Piloten und Flughafen- bzw. DFS-Angestellten, Abgleichen mit offiziellen Daten, ungezählten Stichproben und statistischen Auswertungen bestätigt. Hilfreich hierbei war auch der Data-Bulletproofing-Guide von ProPublica.
Umsetzung mit ProPublica-Datenjournalisten
Nun mussten wir einen Weg finden, eine Datenbank aufzubauen, die Daten visuell umzusetzen und Geschichten aus den Zahlen zu gewinnen. Dafür bewarb ich mich in dem Datenjournalismus-Team von ProPublica in New York für das von der Knight Foundation unterstützte P5-Stipendium. In mehreren Telefonkonferenzen präsentierte ich das Projekt. Scott Klein und seine Kollegen fanden es spannend. Und einen Monat später, im November 2012, saß ich schon im Flieger nach New York.

Hier entstand der Prototyp des Flugrouten-Radars
Dort baute ich gemeinsam mit Jeff Larson und Al Shaw ein Grundgerüst mit dem Framework Ruby on Rails. Weil wir uns mit den Flugspuren im dreidimensionalen Raum befanden, wählten wir als Datenbank PostGIS, eine Erweiterung von PostgreSQL, die mit komplizierten Geoberechnungen umgehen kann. Damit kann etwa ganz leicht festgestellt werden, ob eine Polyline (Flugspur) in einem Polygon (Ortsteil) liegt.
Nach zwei Wochen hatten wir eine Anwendung programmiert, die genau das tat, was wir ursprünglich wollten: Überflüge über Ortsteilen und Gemeinden automatisch zählen sowie Ranglisten erstellen. Außerdem konnten Nutzer nach der Adresseingabe Flüge in einem gewissen Radius über ihrem Standort sehen. Erst noch in 2-D von oben.
3-D-Visualisierung im Browser ohne Plugins
Jeff experimentierte aber an einer 3-D-Darstellung der Flugrouten, da diese so auch bei größerem Flugaufkommen durch die horizontale Fächerung übersichtlicher und realistischer dargestellt werden können.

Erster Prototyp der 3-D-Karte von Jeff Larson
Zwar gibt es 3-D-Karten wie etwa die von Nokia Maps, wie die von Apple oder Google auf Smartphones, Experimente auf Basis von Open Street Maps und natürlich Google Earth. Allerdings benötigt man für viele von ihnen Plugins wie etwa WebGL (Web Graphics Library), die nicht von allen Endgeräten unterstützt werden.
Da wir eine plattformübergreifende Anwendung veröffentlichten wollten, bedienten wir uns einer eigenen Lösung, einer Mischung aus CSS-3-D-Transforms, SVG-Vektoren und statischen Karten. Dabei wird der entsprechende Kartenausschnitt per CSS geneigt und die Flugspuren mit raphael.js als Vektoren auf Basis der Flughöhe projiziert.
Mapbox, Leaflet und Yahoo statt Google
Google stellt mit seinen Maps– und Geocoding-Diensten mitunter die besten auf dem Markt. Bei der Berliner Morgenpost kamen die Tools häufig zum Einsatz. Diesmal haben wir uns aber dagegen entschieden. Das hat zwei Gründe: Google verlangt viel Geld bei kommerzieller Nutzung über ein gewisses Kontingent (z.B. bei mehr als 2500 Geocoder-Abfragen) hinaus. Außerdem verbietet Google in seinen AGB die 3-D-Darstellung seiner Karten.

Google, OSM, Mapbox, Nokia hier vergleichen: http://bit.ly/16liEFI
Nach einigen Tests und Vergleichen entschieden wir uns für die Karten von Mapbox. Die basieren auf den Daten der offenen Kartensoftware Open Street Maps. Die Straßen der Hauptstadtregion (Berlin und angrenzende Brandenburg-Gemeinden) sind dort nahezu 100% exakt erfasst. Mapbox bietet darüber hinaus eine Static-API für statische Tiles, die wir für die 3D-Darstellung benötigen. Außerdem lassen sich die Karten mit dem Tool Tilemill sehr einfach stylen. Mapbox bietet in der Bezahlvariante sogar mehr oder weniger brauchbare Satelliten-Bilder. Die 2-D-Karten wurden mit dem Framework Leaflet umgesetzt.
In der Anwendung kam ursprünglich Nominatim, der kostenlose (Reverse-)Geocoder von Open Street Maps, zum Einsatz. Der Dienst funktioniert zwar relativ gut und schnell, allerdings sind vor allem in Brandenburg und Berliner Randbezirken nicht alle Hausnummern indexiert. Da unsere Anwendung aber auf dem Geocoder als zentrales Element basiert, waren uns exakte Treffer bis auf Hausnummern wichtig. Wir entschieden uns also für den kostenpflichtigen Placefinder von Yahoo. In seiner Treffergenauigkeit kommt er dem Google-Geocoder schon sehr nahe.
D3, Responsive, Permalinks
„If it doesn’t work on mobile, it doesn’t work!“ Wir haben die Anwendung nicht nur mobiloptimiert, da immer mehr Nutzer die Berliner Morgenpost per Smartphones und Tablets besuchen. Mit der Standortsuche bieten wir auch ein Feature, das den Flugverkehr direkt über dem aktuellen Standort zeigt. Ohne Adresseingabe, sondern mit der HTML5 Geolocation API. Die Ansicht passt sich aufgrund des Responsive Designs der Größe des Gerätes automatisch an.
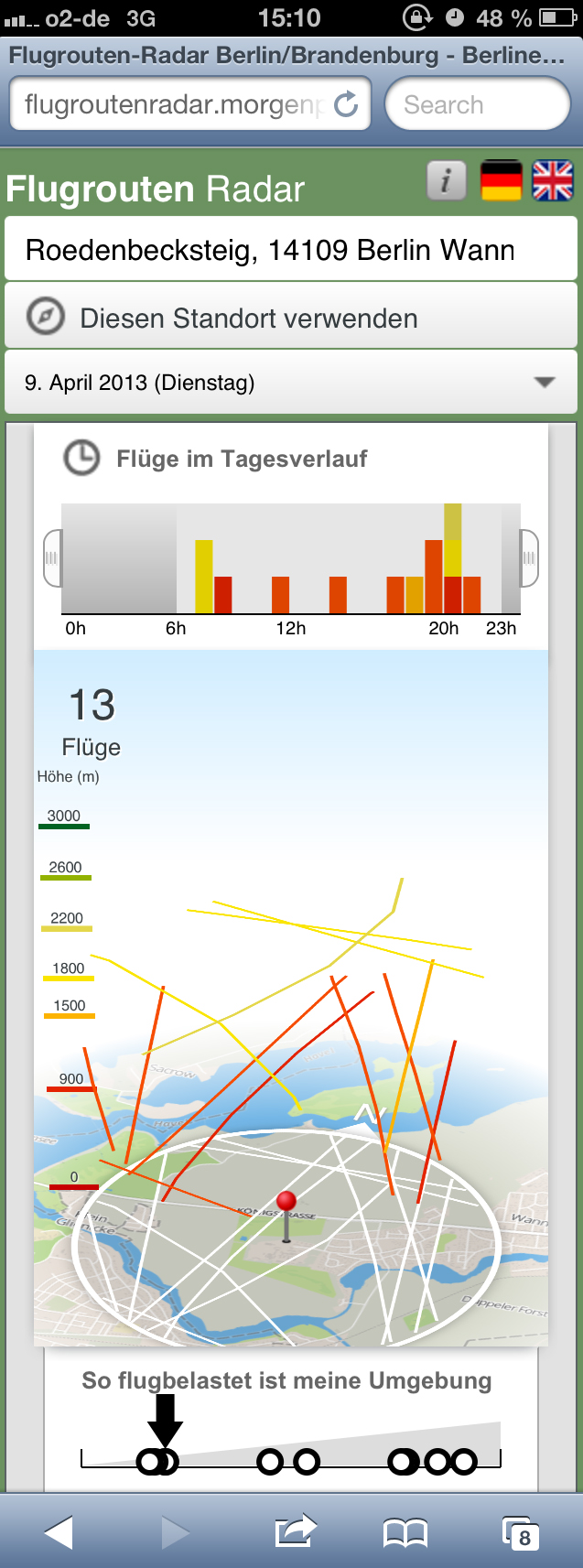
Responsive Design passt sich an Endgeräte an
Dieses Vorhaben stellte sich als sehr kompliziert heraus, weil die Hauptseite der Berliner Morgenpost nicht responsive ist. Wir wollten die Anwendung aber nahtlos in unser Angebot integrieren. Außerdem konnten wir den Flugrouten-Radar nicht wie unsere bisherigen interaktiven Anwendungen bei der Berliner Morgenpost einfach als iframe einbinden. Ein Nachteil unserer früheren interaktiven Anwendungen war nämlich, dass sie eine URL haben, die einen bestimmten Anfangszustand zeigt. Wir wollten aber jeden Zustand und damit Einzelerkenntnisse der Anwendung bookmarkbar und teilbar machen. Die Adresse passt sich also jedem Zustand an und kann dann etwa bei Twitter, Facebook und Google+ geteilt werden. Die Lösung war eine hauseigene API, mit der Seitenteile dynamisch zugeschaltet werden können.
Für die Darstellung der Balkendiagramme kam DC.js, eine Erweiterung von Crossfilter basierend auf D3 (Data-Driven Documents) zum Einsatz. Für Balken- und Liniendiagrammen in unseren Artikeln nutzen wir Datawrapper.
Ausbau, weitere Ideen, Lehren
Wir wollen die historischen und täglich aktuellen Daten mit weiteren Daten verknüpfen. Auch wollen wir noch mehr den Fokus auf Prognosen für die künftigen BER-Routen mit dem Hintergrund der Einzelfreigaben-Praxis legen. Außerdem planen wir Twitter-Accounts, die automatisiert entsprechende Daten twittern. Darüber hinaus denken wir auch über eine Foursquare-Lösung nach, wie sie etwa ProPublica für eine Datengeschichte umgesetzt hat. Auch wollen wir Ideen in Richtung Crowdsourcing umsetzen.
Das Benutzerinterface entsteht
Als besonders trickreich hat sich die 3-D-Karte als zentrales Element der Anwendung herausgestellt. Sie basiert auf nicht standardisierten Features und ist daher sehr experimentell. Besonders Chrome und iOS hatten Probleme, dass wir auf diesen Systemen die Anzahl der angezeigten Flugspuren begrenzen mussten. Auch funktioniert die 3-D-Karte nicht mit dem Internet Explorer, der das dafür nötige „preserve-3d“ nicht unterstützt.
Außerdem hatten wir viele Erkenntnisse erst während der Arbeit mit den Daten und der Anwendung. Da es uns aber aufgrund unserer knappen Deadline nicht möglich war, den Flugrouten-Radar und dessen Logik dahinter immer wieder umzuwerfen, fehlen einige Features, die wir zum Start eigentlich gerne noch gehabt hätten.
Da wir den Flugrouten-Radar aber nicht als für immer abgeschlossene Anwendung, sondern eher als Prozess sehen, wollen wir die Funktionalität weiter verbessern und immer den aktuellen Möglichkeiten des Web anpassen. Währenddessen wird die Datenbank ein täglich umfangreicheres Recherchetool, das die Redaktion mit dem Tool pgAdmin befragen kann.
Der Flugrouten-Radar ist unsere LP. Es wird davon noch viele Single-Auskopplungen geben. Und bis zur BER-Eröffnung sind ja vermutlich noch ein paar Jahre Zeit für neue Features und Geschichten.
Über Kritik, Hinweise, Anregungen freue ich mich hier in den Kommentaren, bei Twitter, Facebook und Google+
")





